The Checklist
In your compciv-2016 Git repository create a subfolder and name it:
exercises/0003-requests-sotuThe folder structure will look like this (not including any subfolders such as `tempdata/`:
compciv-2016
└── exercises
└── 0003-requests-sotu
├── a.py
├── b.py
├── c.py
├── d.py
├── e.py
├── f.py
Background information
With every State of the Union address, it's a common data news story to analyze what's been said over the years.
Here's how The Atlantic did it last year:
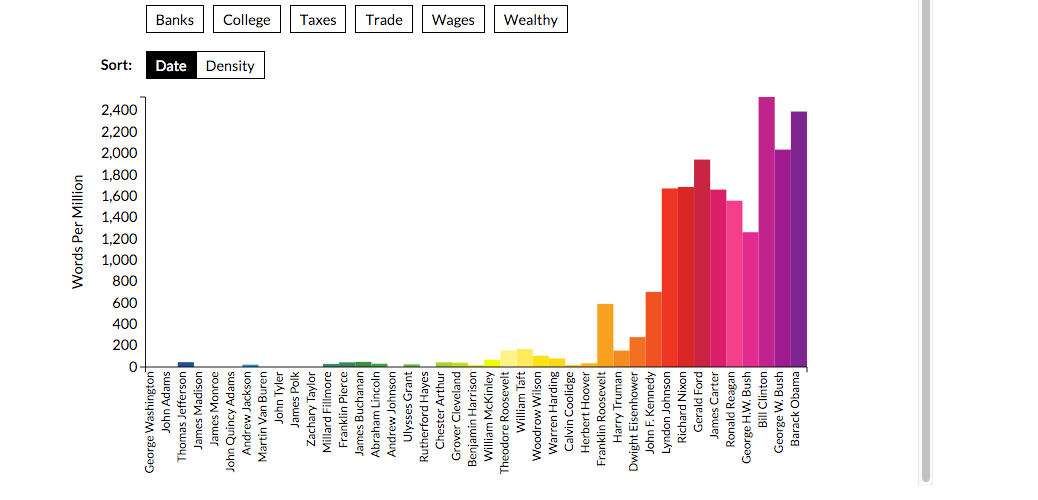
Here's a fancy visualization by the Washington Post:
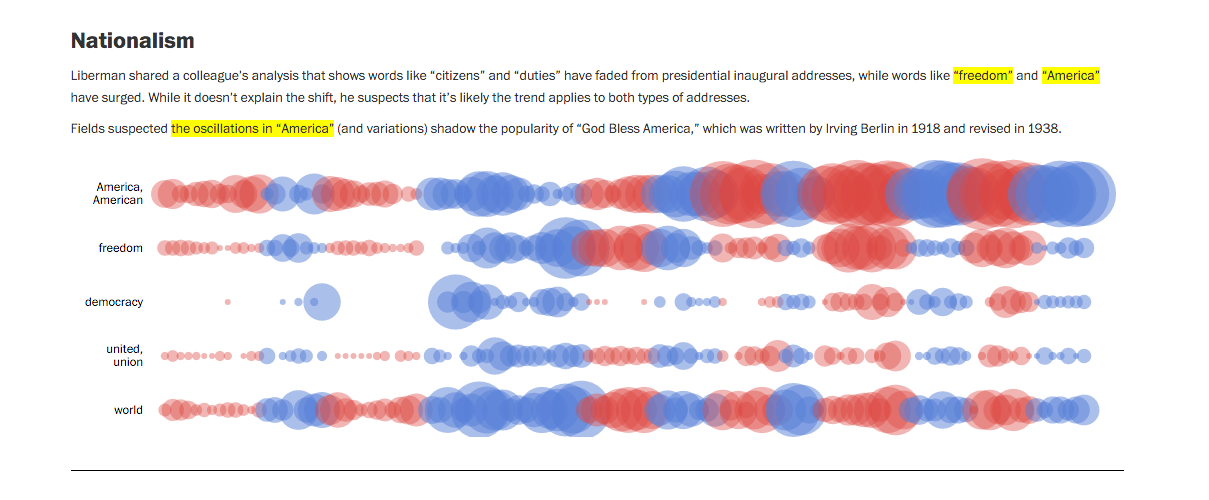
And why restrict ourselves to States of the Union? All of Obama's speeches and remarks can be found here. NPR did a word analysis of those, except focused on the things that the press corps asked:
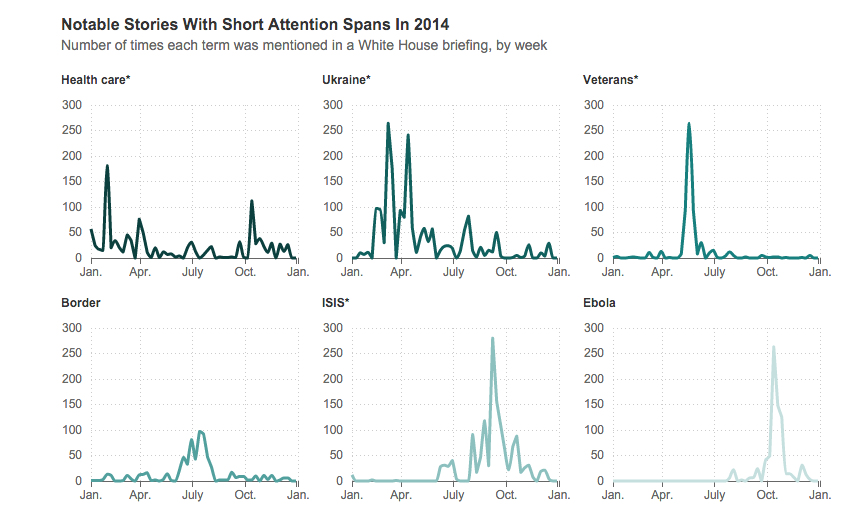
NPR even did an analysis of the cadence of President Obama's speeches.
All of these involve different levels of insight and data-wrangling. But at the core of each analysis is simply: gather up the speeches and count up the words.
For this exercise, we will focus on President Obama's State of the Union addresses, just to get acquainted with basic web request operations and text searching. In future exercises, we'll learn more techniques and libraries for more expansive searches, but the core process will be the same.
About the Requests library
Our primary library for downloading data and files from the Web will be Requests, dubbed "HTTP for Humans".
To bring in the Requests library into your current Python script, use the import statement:
import requests
You have to do this at the beginning of every script for which you want to use the Requests library.
Note: If you get an error, i.e. ImportError, it means you don't have the requests library installed. Email me if you're having that issue, because it likely means you probably don't have Anaconda installed properly.
The get method
The get method of the requests module is the one we will use most frequently – which corresponds to how the majority of the HTTP requests your browser makes involve the GET method. Even without knowing much about HTTP, the concept of GET is about as simple as its name: it will get a resource from a web server.
The get() method requires one argument: a web URL, e.g. http://www.example.com. The URL's scheme – i.e. "http://" – is required, even though you probably never type it out in your browser.
Run this from the interactive prompt:
>>> requests.get("http://www.example.com")
<Response [200]>
You might have expected the command to just dump the text contents of http://www.example.com to the screen. But it turns out there's a lot more to getting a webpage than just getting what you see rendered in your browser.
You can see this for yourself by popping open the Developer Tools (in Chrome, for OSX, the shortcut is: Command-Alt-J), clicking the Network panel, then visiting a page:
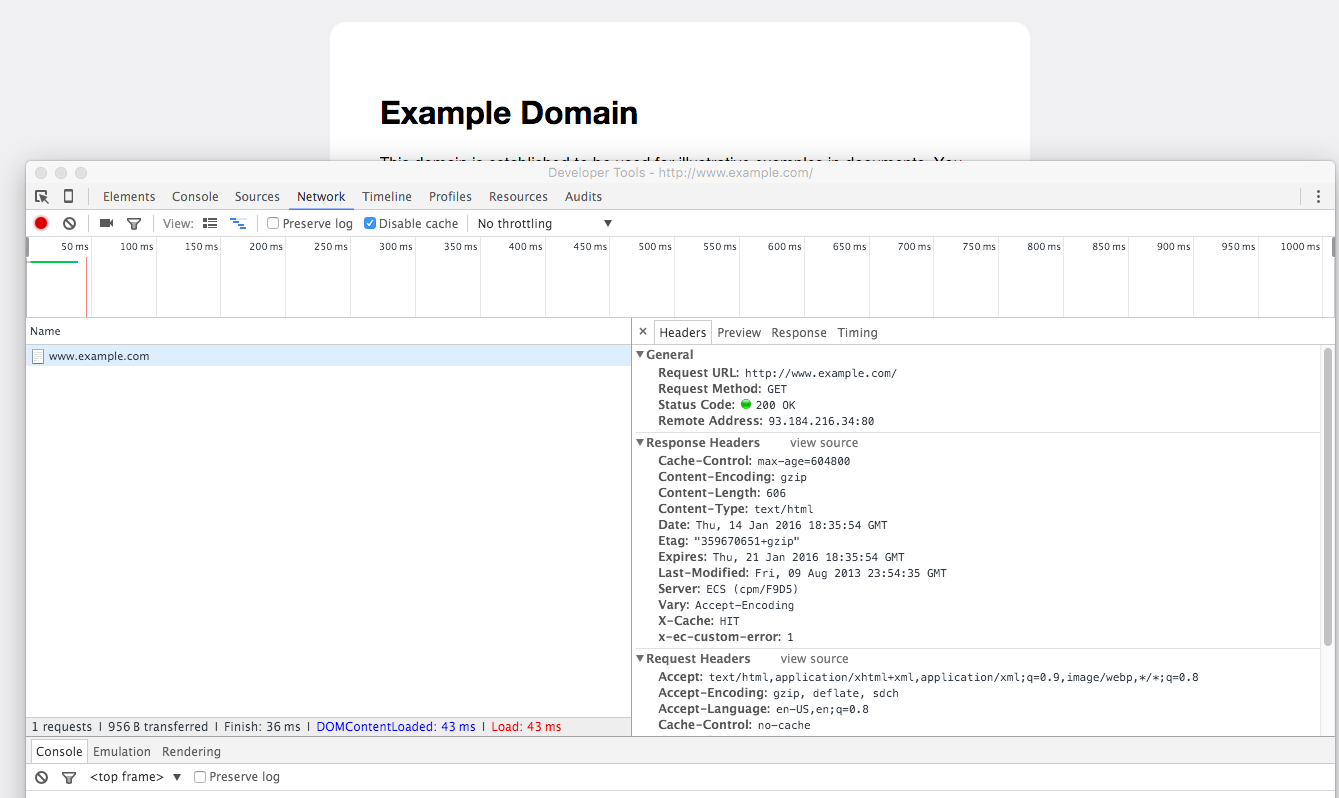
What each of those various attributes mean isn't important to figure out now, it's just enough to know that they exist as part of every request for a web resource, whether it's a webpage, image file, data file, etc.
Returning to our previous code snippet, let's assign the result of the requests.get() command to a variable, then inspect that variable. I like using resp for the variable name – short for "response"
>>> resp = requests.get("http://www.example.com")
Use the type() function to see what that resp object actually is:
>>> type(resp)
requests.models.Response
If you want to get the text of a successful requests.get() response, use its text attribute:
>>> resp = requests.get("http://www.example.com")
>>> print(resp.text)
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
# .... and so on
So that's the basics of just getting the contents of a webpage. Here's a little more explanation of the concepts:
A quick primer on objects and their methods and attributes
The concept of "objects" in programming is a complicated, and somewhat boring and confusing topic that's easier to explain by example. This is a segue into introducing the concept, just so that you have some context when trying to access the data/contents, etc. after successfully downloading a webpage via requests.get().
Here's a brief overview of what you need to know about objects for this lesson:
- Use the
type()function to find out the type of an object, e.g.type('hello') - Getting a web resource means getting all of the metadata involved in the transaction. Thus, the
requests.get("http://somepage.com")method returns an object of typerequests.models.Response, not just a text string ofsomepage.com's raw HTML. - Objects have methods and attributes. Different objects have different methods and attributes.
- At the interactive Python prompt, use the Tab key to autocomplete names of methods and attributes belonging to the object that a particular variable refers to. This is a much better alternative than trying to memorize everything.
- Methods and attributes will feel like the same kind of concept. Practically speaking, invoking a method requires including the closed parentheses:
"hello world".upper(). Attributes do not require the parentheses, e.g.9.denominator - To get the raw text of a webpage from a
requests.models.Response, use itstextattribute.
And here's a longer explanation:
So what is that requests.models.Response?
Just as "hello world" is an object of the type str (i.e. string literal) and 42 is an object of type int (i.e. integer), the object returned by requests.get(), and subsequently assigned to the resp variable, has its own type: requests.models.Response.
Each type of object has its own methods and attributes that can be referenced. The difference between a method and attribute can be…confusing…so for awhile, it may be a matter of memorization and just knowing how to inspect things.
Methods
Think of methods as functions that belong to an object (type() and print() are examples of functions that are called without being part of an object).
For instance, the str object has a method named upper() (return an upper-cased version of the string):
>>> "Hello world".upper()
'HELLO WORLD'
It doesn't make sense to call upper() all by its lonesome, i.e.
>>> upper()
…because there is nothing to translate to uppercase. The upper() (and its counterpart, lower()) method only makes sense in the context of a text string. Hence, we think of upper() as being a method that belongs to the String object.
You can think of methods as referring to things that require an "action" or calculation of some sort, e.g. "hello world".upper() executes an action in which the characters of "hello world" are translated into their upper-case equivalents: "HELLO WORLD". The use of the closed parentheses is what executes that action. If you don't include the parentheses, nothing happens except Python telling you, "Yep, that's a function"
>>> 'hello world'.upper
<function str.upper>
Attributes
Think of attributes as properties inherent to an object – i.e. no calculation or action is required to derive them – they just are. For example, a person's birthdate can be thought of as an attribute – an unchangeable fact about that person. But a person's age is better thought of as a method – because age is derived from birthdate, i.e. finding the difference between the current date and the birthdate.
For our practical purposes, attributes are referenced the same way as methods, but without the use of closed parentheses:
>>> a = 42
>>> a.numerator
42
>>> a.denominator
1
Exploring the methods and attributes of requests.models.Response
Because the requests.models.Response object encapsulates
Let's use the autocomplete functionality of interactive Python to get a list of methods and attributes belonging to the requests.models.Response object.
Starting from the very beginning, including the import statement:
>>> import requests
>>> resp = requests.get("http://www.example.com")
At the next prompt, type out resp, then the dot. Then, hit Tab – the interactive prompt should return a list of all possible methods and attributes:
>>> resp. #( hit the Tab key)
resp.apparent_encoding resp.iter_lines
resp.close resp.json
resp.connection resp.links
resp.content resp.ok
resp.cookies resp.raise_for_status
resp.elapsed resp.raw
resp.encoding resp.reason
resp.headers resp.request
resp.history resp.status_code
resp.is_permanent_redirect resp.text
resp.is_redirect resp.url
resp.iter_content
The text attribute contains the raw HTML of the webpage you requested. It's just a String object, which you can verify for yourself:
>>> type(resp.text)
str
And you can use the len() function to get the number of characters:
>>> len(resp.text)
1270
The status_code attribute
Check out the HTTP Status Cats photo gallery (or HTTP Status Dogs, if you prefer dogs) for an informal overview of HTTP status codes.
Then find the status code of the response that you received with the status_code method:
>>> resp.status_code
200
We'll use a few other of the attributes and methods of the requests.models.Response in other situations. But text and status_code will fulfill the majority of our needs.
The Exercises
0003-requests-sotu/a.py » An example webpage request with requests and example.com
Use the Requests library to get the URL, http://example.com.
Print out the response’s status code, length of the text response (i.e. you’ll have to use the len() function), and the URL.
When you run a.py from the command-line:
0003-requests-sotu $ python a.py
-
The program's output to screen should be:
200 1270 http://example.com/
Note that the
urlattribute of the response object is not exactly the same as the URL that you attempted to retrieve. This is a common phenomenon, especially when the destination URL redirects you to another page (such as a bit.ly URL shortener, e.g.https://bit.ly/a)
0003-requests-sotu/b.py » Cause a ConnectionError
Write a program that prints out the name of a URL that you want to get.
Then, that program should crash due to a runtime error of type ConnectionError, which will happen if you try to connect to a non-existent web server. Or, if your own Internet connection is down (obviously, the former is easier to specify in your script).
When you run b.py from the command-line:
0003-requests-sotu $ python b.py
-
The program's output to screen should be:
#[the URL you attempt to GET should be printed here]
- The program should crash because of a ConnectionError
Ideally, programs that we write are reproducible and deterministic. But one of the tricky things about programming against online data – or any kind of external resource – is that you can never be sure that when your script runs that the external resource is actually available. The web server, or your Internet connection, might have gone down since you last ran the script.
0003-requests-sotu/c.py » Crash your program with a MissingSchema error
Write a program that prints out the name of a URL that you want to get (technically, this URL should be invalid….)
Then, that program should crash due to a runtime error of type MissingSchema.
When you run c.py from the command-line:
0003-requests-sotu $ python c.py
-
The program's output to screen should be:
#[the URL you attempt to GET should be printed here]
- The program should crash because of a MissingSchema
Browsers do a lot for us, even when it comes to resolving the URLs that we manually type in. Because a web browser is used to visit, well, webpages, a browser usually just fills in
http://if we omit it – and this is perfectly fine 99.9% of our casual browser usage. However, the Requests library doesn’t provide that convenience, so it’s good to get acquainted with the corresponding error message.
0003-requests-sotu/d.py » Fetch President Obama's 2016 State of the Union Address
Basically the same as exercise a.py, except using this specific URL:
Print out the status code, the length of the text, and the URL of the response.
When you run d.py from the command-line:
0003-requests-sotu $ python d.py
-
The program's output to screen should be:
200 147766 # approximately https://www.whitehouse.gov/the-press-office/2016/01/12/remarks-president-barack-obama-%E2%80%93-prepared-delivery-state-union-address
Once you know how to get one kind of webpage, you basically have the pattern for getting any (public) webpage or web resource
0003-requests-sotu/e.py » Count up the times "Applause" is used in the 2016 SOTU webpage
The raw HTML of a webpage is just text, i.e. a String object. String objects in Python have the count() method, which takes in a single argument – another string object to search for – and returns an integer, representing how many times that string was found in the invoking string:
>>> a = "hello world"
>>> a.count('world')
1
>>> a.count('o')
2
For this exercise, print out the following calculations for the webpage of the 2016 State of the Union address
- The number of times the string
"Applause"appears. - The number of times the string
"Applause"appears regardless of case, i.e."APPLAUSE","applause", etc. - The number of times “
<p>” appears.
Hint:
- Don’t try to guess all the different ways
"Applause"can be capitalized. Use thelower()orupper()methods to convert all of the characters in the HTML into one case or the other, than search accordingly. - |
Since
upper()andlower()both return string objects, you can chain method calls like this:"hello world".upper().count("L") - | The fact that the results for #2 and #3 are the same is a weird coincidence. I guess we can interpret that as: President Obama received applause for every paragraph-long statement he made, on average.
When you run e.py from the command-line:
0003-requests-sotu $ python e.py
-
The program's output to screen should be:
84 89 89
Why does “<p>” appear so many times in the HTML, but we don’t see it at all when we view the URL via browser? That’s the point of HTML – it includes a bunch of meta information that your browser uses to render the page. But the raw HTML itself is not shown. Our simple program doesn’t know how to parse HTML in such a way that ignores the HTML tags…but we will learn that soon…
0003-requests-sotu/f.py » Count up the times "Applause" is used in all of the webpages for Obama's States of the Union
Similar to the previous exercises, except repeated for all of the States of the Union during Obama’s presidency (technically, 2009’s was not a SOTU address, but we’ll count it anyway).
Here are the URLs:
- https://www.whitehouse.gov/the-press-office/remarks-president-barack-obama-address-joint-session-congress
- https://www.whitehouse.gov/the-press-office/remarks-president-state-union-address
- https://www.whitehouse.gov/the-press-office/2011/01/25/remarks-president-state-union-addressehouse.gov/the-press-office/2012/01/24/remarks-president-state-union-address
- https://www.whitehouse.gov/the-press-office/2013/02/12/remarks-president-state-union-address
- https://www.whitehouse.gov/the-press-office/2014/01/28/president-barack-obamas-state-union-address
- https://www.whitehouse.gov/the-press-office/2015/01/20/remarks-president-state-union-address-january-20-2015
- https://www.whitehouse.gov/the-press-office/2016/01/12/remarks-president-barack-obama-%E2%80%93-prepared-delivery-state-union-address
For each URL, print out:
- The URL of the response
- The number of characters in the text of each response
- The number of times “Applause” appears in the text of each response, case-insensitive
- If you already know how to do a for-loop and how to iterate across a collection of objects in Python, you should do that. If you don’t, there’s nothing wrong with repeating the same code, over and over, for each URL. It should feel really annoying, though, so keep that in mind when we discuss loops and collections and other slightly more complicated data objects.
When you run f.py from the command-line:
0003-requests-sotu $ python f.py
-
The program's output to screen should be:
https://www.whitehouse.gov/the-press-office/remarks-president-barack-obama-address-joint-session-congress 146186 # approximately 0 https://www.whitehouse.gov/the-press-office/remarks-president-state-union-address 157621 # approximately 116 https://www.whitehouse.gov/the-press-office/2011/01/25/remarks-president-state-union-address 155070 # approximately 80 https://www.whitehouse.gov/the-press-office/2012/01/24/remarks-president-state-union-address 157847 # approximately 87 https://www.whitehouse.gov/the-press-office/2013/02/12/remarks-president-state-union-address 156855 # approximately 87 https://www.whitehouse.gov/the-press-office/2014/01/28/president-barack-obamas-state-union-address 152266 # approximately 0 https://www.whitehouse.gov/the-press-office/2015/01/20/remarks-president-state-union-address-january-20-2015 156269 # approximately 86 https://www.whitehouse.gov/the-press-office/2016/01/12/remarks-president-barack-obama-%E2%80%93-prepared-delivery-state-union-address 147766 # approximately 89