The problem
Here's the problem we're trying to solve – if you're doing this as homework, see the full info for this exercise:
Like downloading files, unzipping files is more complicated when you do it programmatically. The zip file might not unpack its contents where you thought it would…
When you run c.py from the command-line:
0004-shakefiles $ python c.py
-
The program's output to screen should be:
Unpacked tempdata/matty.shakespeare.tar.gz into: tempdata
-
The program creates this file path:
tempdata/comedies(directory) -
The program creates this file path:
tempdata/histories(directory) -
The program creates this file path:
tempdata/poetry(directory) -
The program creates this file path:
tempdata/tragedies(directory)
The unpack_archive() function
The shutil function that we care about right now is [unpack_archive()]((https://docs.python.org/3/library/shutil.html), which unpacks all kinds of archived file formats, include gz and zip files.
Assuming you have a archive file named example.zip, here's the code to unzip it with shutil:
>>> import shutil
>>> shutil.unpack_archive("example.zip")
Wherever you are running your code – or wherever you started ipython, it will dump the contents of example.zip there.
Pretend foo.py has the unzipping code, as shown in the previous snippet.
Pretend your file directory looks like this:
Desktop
├── somepath ## <== YOU ARE HERE
├── foo.py
├── tempdata
├── example.zip
If you are in the Desktop/somepath directory, and then try to run foo.py like so:
$ python foo.py
Then you can expect the contents of example.zip to be unpacked where foo.py exists. The same result will happen if you run shutil.unpack_archive("example.zip") after starting ipython in the Desktop/somepath directory.
Desktop
├── somepath ## <== YOU ARE HERE
├── foo.py
├── example.contents ## <== what just got unpacked
├── tempdata
├── example.zip
It doesn't matter that example.zip is inside tempdata. Its contents are by default unzipped wherever the unzipping program was called from, i.e. the somepath directory.
To underscore the point, pretend you are actually in Desktop, and you run your script like this (it's possible to run a script without being in the same directory by specifying all the subdirectories to get to the script):
$ python somepath/foo.py
Guess where the files end up?
Desktop ## <== YOU ARE HERE
├── example.contents ## <== what just got unpacked
├── somepath
├── foo.py
├── tempdata
├── example.zip
We need a way to tell unpack_archive() to dump its work in a specific directory, i.e. Desktop/somepath/tempdata/
How to specify the exact path to extract an archive's contents into
Frequently, unzipping a file's contents into your current working directory leaves a mess. This is why we have that tempdata subdirectory for our homework assignments. The unpack_archive() function takes a second named argument, extract_dir, in which we can specify a directory to unzip the files into:
(this assumes tempdata is a subdirectory relative to wherever you started the interactive prompt from):
>>> shutil.unpack_archive("example.zip", extract_dir="tempdata")
Shakespeare zip, all together
Before moving on, this lesson assumes you've completed the previous two lessons:
- How to create a directory idempotently with makedirs() - the result of this exercise is that you have a subdirectory named
tempdata - Downloading and saving the Shakespeare zip with requests - the result of this exercise is that you have downloaded a file into
tempdatanamedmatty.shakepeare.tar.gz
Assuming you're reading this guide because you're trying to finish the Shakespeare zip-file homework, here are all the steps, from creating a new subdirectory named tempdata, downloading the Shakespeare zip file into it, and then unpacking it to tempdata.
(Note that in the homework assignment, all of these steps are actually their own mini-scripts. That's to emphasize how discrete each operation is.)
Remember that you have to be inside the particular exercise's directory if you intend for tempdata and the subsequent files to be inside of that directory:
Desktop
└── compciv-2016
└── exercises
└── 0004-shakefiles ## <== YOU ARE HERE
├── a.py
├── b.py
├── c.py
Importing the libraries
We need three libraries/modules:
import os
import requests
import shutil
Creating the tempdata subdirectory
The makedirs() function is part of the os module:
os.makedirs("tempdata", exist_ok=True)
Downloading the zip file
By the time this code runs, it assumes tempdata subdirectory has been created and the requests library has been imported.
We use requests.get() to download the URL. Then we store the content of the response in the zipdata variable.
zipurl = 'http://stash.compciv.org/scrapespeare/matty.shakespeare.tar.gz'
resp = requests.get(zipurl)
zipdata = resp.content
Saving the zip file
Before we can unzip the file, we need to save – i.e. write it to disk.
Programatically generate the file path
On Linux/OSX, the file path that we want to save to is:
tempdata/matty.shakespeare.tar.gz
Let's use os.path.join() to generate that path (yes, even as simple as that path is):
zname = os.path.join("tempdata", "matty.shakespeare.tar.gz")
No special libraries are needed as this just requires the open() function, and the the file's write() function. We assume that the zipdata variable contains the bytes of a downloaded zip file:
zfile = open(zname, "wb")
zfile.write(zipdata) # i.e. resp.content
zfile.close()
Unzipping the zip file
The unpack_archive() function comes to us via the shutil module. Remember that we have to provide the named argument, extract_dir. Even though the zip file is inside the tempdata subdirectory, i.e. "tempdata/matty.shakespeare.tar.gz", the Python interpreter assumes we want to unzip it from where our Python script is being executed, i.e. outside of (one level above) tempdata.
We do not want that. So that's why we provide the extract_dir argument.
Assuming the zname variable holds the saved zip file:
shutil.unpack_archive(zname, extract_dir='tempdata')
If you are following the compciv-2016 exercise set, 0004-shakefiles, then switch to your Desktop operating system and see if the files successfully unpacked inside your compciv-2016/exercises directory, e.g. ~/Desktop/compciv-2016/exercises/0004-shakefiles:
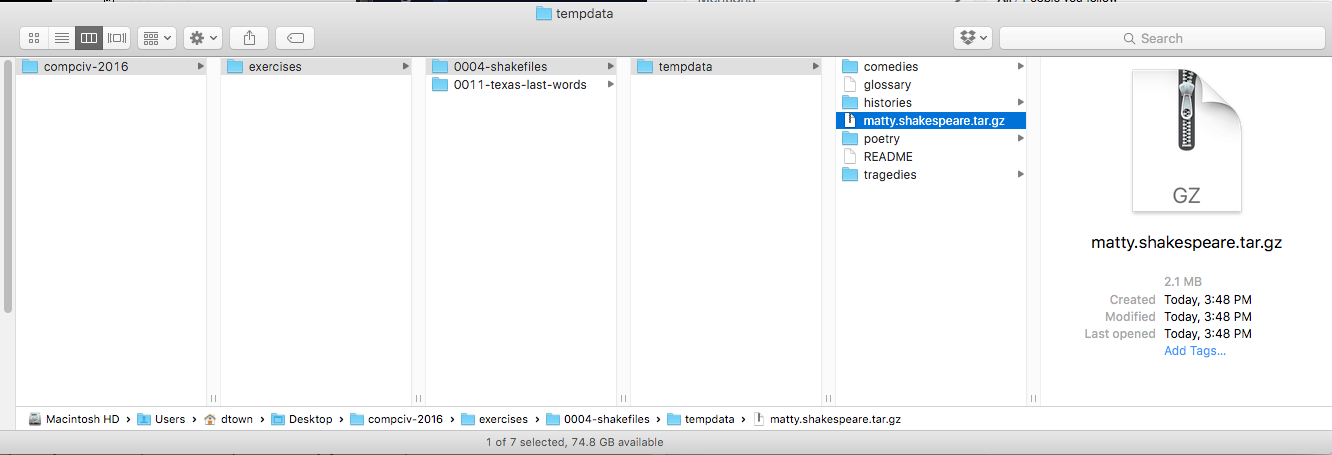
Or, if you prefer seeing it as a plaintext tree. Take special note how everything is inside tempdata:
Desktop
└── compciv-2016
└── exercises
└── 0004-shakefiles ## <== YOU ARE HERE
├── a.py
├── b.py
├── c.py
├── d.py
├── e.py
├── f.py
├── g.py
├── h.py
├── i.py
└── tempdata
├── README
├── comedies
│ ├── allswellthatendswell
│ ├── asyoulikeit
│ ├── comedyoferrors
│ ├── cymbeline
│ ├── loveslabourslost
│ ├── measureforemeasure
│ ├── merchantofvenice
│ ├── merrywivesofwindsor
│ ├── midsummersnightsdream
│ ├── muchadoaboutnothing
│ ├── periclesprinceoftyre
│ ├── tamingoftheshrew
│ ├── tempest
│ ├── troilusandcressida
│ ├── twelfthnight
│ ├── twogentlemenofverona
│ └── winterstale
├── glossary
├── histories
│ ├── 1kinghenryiv
│ ├── 1kinghenryvi
│ ├── 2kinghenryiv
│ ├── 2kinghenryvi
│ ├── 3kinghenryvi
│ ├── kinghenryv
│ ├── kinghenryviii
│ ├── kingjohn
│ ├── kingrichardii
│ └── kingrichardiii
├── matty.shakespeare.tar.gz
├── poetry
│ ├── loverscomplaint
│ ├── rapeoflucrece
│ ├── sonnets
│ ├── various
│ └── venusandadonis
└── tragedies
├── antonyandcleopatra
├── coriolanus
├── hamlet
├── juliuscaesar
├── kinglear
├── macbeth
├── othello
├── romeoandjuliet
├── timonofathens
└── titusandronicus
As one more test to make sure things are in the right place, try running this (inside the exercise set's directory, i.e. 0004-shakefiles) – the output to screen should be the first 25 lines of the Hamlet text:
import os
fname = os.path.join("tempdata", "tragedies", "hamlet")
f = open(fname, 'r')
for x in range(25):
print(f.readline().strip())
f.close()
If you've gotten this far, then you're ready to move on to the next exercises that involve actually reading and processing the Shakespeare texts.