The problem
Here's the problem we're trying to solve – if you're doing this as homework, see the full info for this exercise:
Open the file at tempdata/tragedies/romeoandjuliet and read and print the final 5 lines.
This seems like the same exercise as d.py – except that we read from Romeo and Juliet instead of Hamlet. And that we read the final 5 lines instead of the first 5 lines.
That first difference is easy to do; that second one is a much different problem to tackle.
When you run f.py from the command-line:
0004-shakefiles $ python f.py
-
The program's output to screen should be:
4762: Some shall be pardon'd, and some punished: 4763: For never was a story of more woe 4764: Than this of Juliet and her Romeo. 4765: 4766: [Exeunt]
Open, read, count then re-open
We're going to solve this exercise in the most straightforward way possible, even if it seems a little wasteful and inefficient.
If we want to print the final 5 lines in Romeo & Julet, we need to know how many lines there are in the first place. Let's do a manual check with the text editor:
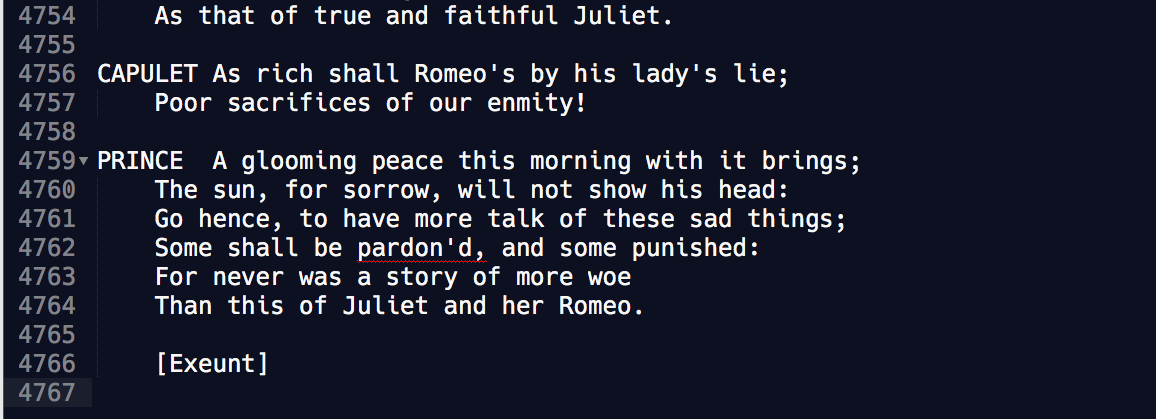
Though the last line number in the text editor is 4767 – it's a blank line (i.e. just a newline character). The line count is technically 4,766.
Now let's count it programmatically; revisiting the code from the previous exercise, in which we counted every line in Hamlet, here's how to count every line in Romeo and Juliet (basically, it's the same code, just change the filename):
import os
fname = os.path.join('tempdata', 'tragedies', 'romeoandjuliet')
txtfile = open(fname, 'r')
line_num = 0
for x in txtfile:
line_num += 1
txtfile.close()
print(fname, "has", line_num, "lines")
The output will be:
tempdata/tragedies/romeoandjuliet has 4766 lines
So how to design the for-loop to begin counting at the 5th-to-final-line and to stop at line 4766? We already know how to use the range() function to create a range of numbers from x to y (x and y are arguments representing, respectively, the start and end points of the range):
for n in range(42, 48):
print(n)
A hardcoded advance
If we were to hardcode the line count of Romeo and Juliet, i.e. 4766, our script for advancing the file to the final 5 lines would look like this – note that we need to call readline() in order to, well, read the line, but we don't print it out:
import os
fname = os.path.join('tempdata', 'tragedies', 'romeoandjuliet')
txtfile = open(fname, 'r')
for n in range(4766 - 5):
txtfile.readline()
When this for-loop exits, it will leave off before line 4761 (i.e. 4766 - 5) (again, think of a cassette tape – or your Netflix scrubber – advancing to the 4761th second of a 4766-second movie).
That means we can use the for line in fileobject type of for-loop to read the final five lines. And in that loop, we will print to screen (again, in this kind of for-loop, an explicit call to readline() is not necessary, as that happens automatically:
(remember that we have to strip() each line of its newline character before passing it into print(), which adds its own newline character)
for line in txtfile:
print(line.strip())
All together:
import os
fname = os.path.join('tempdata', 'tragedies', 'romeoandjuliet')
txtfile = open(fname, 'r')
for n in range(4766 - 5):
txtfile.readline()
for line in txtfile:
print(line.strip())
txtfile.close()
The output:
Some shall be pardon'd, and some punished:
For never was a story of more woe
Than this of Juliet and her Romeo.
[Exeunt]
All together with line numbers
The exercise requires printing the line numbers with each line. So we end up having to manually keep count of the iterations:
import os
fname = os.path.join('tempdata', 'tragedies', 'romeoandjuliet')
txtfile = open(fname, 'r')
line_num = 0
for n in range(4766 - 5):
line_num += 1
txtfile.readline()
for line in txtfile:
line_num += 1
the_line = str(line_num) + ": " + line.strip()
print(the_line)
txtfile.close()
The output:
4762: Some shall be pardon'd, and some punished:
4763: For never was a story of more woe
4764: Than this of Juliet and her Romeo.
4765:
4766: [Exeunt]
Less wasteful counting
If you're a bit more perfectionist, you might think it is wasteful to increment a number during that first for-loop. After all, we know that it ends at 5 lines before the total line count. Here's the previous example re-written to feel a little "tidier". Though keep in mind we're talking about a performance improvement of 0.0001%, and that's probably exaggerating it. I only bring it up as another example of how there are many, many ways to approach the same problem.
There's one more aesthetic change I make: the all-caps'ing of variable names which represent values that are meant to be constant. There's no change in functionality, but uppercasing variables of constant value helps in the readability of the code:
import os
FNAME = os.path.join('tempdata', 'tragedies', 'romeoandjuliet')
TOTAL_LINES = 4766
STARTING_LINE_NUM = TOTAL_LINES - 5 # i.e. when to start printing lines
txtfile = open(FNAME, 'r')
for n in range(STARTING_LINE_NUM):
txtfile.readline() # just read, don't do anything
line_num = STARTING_LINE_NUM
for line in txtfile:
line_num += 1
the_line = str(line_num) + ": " + line.strip()
print(the_line)
txtfile.close()
A variation with a graceful conditional
Computationally-speaking, having one for-loop run right after another does not add any overhead (since the second one begins right where the first one left off). However, doesn't it seem a bit clunky when you describe the algorithm in plain English? We need to read through the lines of a file once, yet we use two for-loops.
There's a way to do this with a single for-loop that reads every line in the file. It involves using a conditional statement to tell the program when to begin printing the lines, instead of just reading them.
Here are the steps in English:
- Given that the line to start from is in the variable
STARTING_LINE_NUM… - Start reading through the file with
readline() - Keep count of the current line number in the
line_numvariable - With each iteration, check to see if
line_numis greater than or equal to the value inSTARTING_LINE_NUM - If not (i.e.
line_num >= STARTING_LINE_NUM is False), then move on to the next iteration. - If it is (i.e.
line_num >= STARTING_LINE_NUM is True), then print the line.
Here's what that looks like; note that there's no need for an else branch, the program execution will just move on to the next loop iteration.
for line_num in range(TOTAL_LINES):
line = txtfile.readline()
if line_num >= STARTING_LINE_NUM:
the_line = str(line_num) + ": " + line.strip()
print(the_line)
Hello, off-by-one error!
If you insert the above code into the main script and re-run it, you'll get subtly incorrect output:
4761: Some shall be pardon'd, and some punished:
4762: For never was a story of more woe
4763: Than this of Juliet and her Romeo.
4764:
4765: [Exeunt]
There are 4,766 lines, and yet the final line number is 4765. What gives?
Remember that the range() function, when called with a single argument, produces a sequence of numbers starting from zero:
>>> for x in range(3):
... print(x)
0
1
2
Which means that if I had wanted to print line 1 – as we normally think of it, I need to add 1 to x (this doesn't change x itself, of course, as there is no reassignment being done):
>>> for x in range(3):
... print(x + 1)
1
2
3
So here's the easiest, most elegant way to fix our problem: manually add 1 to line_num before printing it, i.e: str(line_num + 1):
for line_num in range(TOTAL_LINES):
line = txtfile.readline()
if line_num >= STARTING_LINE_NUM:
the_line = str(line_num + 1) + ": " + line.strip()
print(the_line)
Here is the line in isolation:
the_line = str(line_num + 1) + ": " + line.strip()
If that seems like an incredibly easy thing to screw up (the fundamental issue is forgetting that programming systems typically count from 0), then now [you understand a little better this computer science aphorism:
There are only two hard things in Computer Science: cache invalidation, naming things, and off-by-one errors.
### Variation using txtfile as the iterable
Or, if you prefer the for-loop variation in which txtfile is the iterable object, this means you have to increment line_num yourself. On the other hand, you don't have to call txtfile.readline() manually. And note that I don't have the same off-by-one error as I did in the previous variation.
line_num = 0
for line in txtfile:
line_num += 1
if line_num >= STARTING_LINE_NUM:
the_line = str(line_num) + ": " + line.strip()
print(the_line)
Either way works fine (it's hard to say which one is better, it will depend on the situation, as we will find out in the next exercise…), but notice how the single for-loop vastly simplifies the look of our final script:
import os
FNAME = os.path.join('tempdata', 'tragedies', 'romeoandjuliet')
TOTAL_LINES = 4766
STARTING_LINE_NUM = TOTAL_LINES - 5
txtfile = open(FNAME, 'r')
for line_num in range(TOTAL_LINES):
line = txtfile.readline()
if line_num >= STARTING_LINE_NUM:
the_line = str(line_num + 1) + ": " + line.strip()
print(the_line)
txtfile.close()
I believe that this should run slower than the version with two for-loops, because that line_num >= STARTING_LINE_NUM is a calculation that is done for every iteration (i.e. every line of the file). But this is a calculation that is likely in the nanoseconds – i.e. you could do roughly a billion of them in a second. So…definitely not worth the tradeoff in human readability.